[김건우][AI 기초] 8. K 최근접이웃(KNN) - 훈련세트와 테스트세트 & 데이터전처리
작성자 : 김건우
(2024-04-25)
조회수 : 11903
[YOUTUBE] https://www.youtube.com/watch?v=YVhjkOtAHCI&t=130s
[CODE] 영상 하단 설명란
-----------------------------------------
|
우리는 지난시간에 사이킷런과 맷플롯립을 이용해서 산점도를 그려보았고 K-최근접이웃으로 단순하고 간단한 알고리즘을 어떻게 사용하는지 방법을 배웠습니다. |
| Fit와 score 메서드를 통해서 준비한 데이터를 훈련시켰고, 얼마나 훈련이 잘 되었는지 정확도를 출력했어요. 그리고 마지막에 훈련데이터가 아닌 새로운 데이터를 넣어서 predict 메서드로 결과를 확인해 봤어요. 이렇게 3개의 메서드는 다른 알고리즘도 동일하게 사용하기 때문에 흐름을 꼭 기억해주세요. |
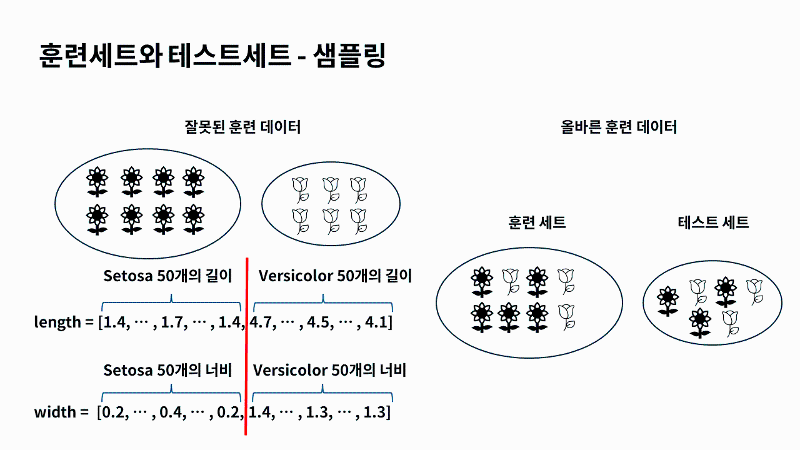
| 하지만 여기서 한번 더 생각해봐야 할 부분이 있는데요. score에서 정확도가 100%가 나왔지만, 기존에 학습시킨 데이터를 AI로 훈련시키고 AI가 이미 결과를 알고 있는데, 그 데이터로 결과를 출력하면 모두 맞추는게 당연하고 못맞추는게 이상하지 않나요? 기말고사를 보기전에 출제될 시험 문제와 정답을 미리 알려주고 시험을 본다면 시험의 의미가 없겠죠? 머신러닝도 이와 유사하게 연습문제와 시험문제가 달라야 올바르게 평가할 수 있듯이, 알고리즘의 성능을 제대로 평가하려면 훈련 데이터와 테스트 데이터로 각각 다르게 구성되어야 해요. 그래서 우리는 세토사와 버시카라의 데이터를 연습문제와 시험을 볼 테스트문제로 나누어야 할 겁니다. 이렇게 만드는 가장 간단한 방법은 기존에 가지고 있는 데이터에서 일부를 떼어내서 활용하는 건데요. |
|
코딩을 통해서 이를 구현하기 위해서는 기존에 준비한 2차원 배열을 두개로 분리하는 방법이 있겠죠? 우리가 사전에 준비한 배열은 세토사 50개에 버시카라 50개가 순서대로 나열되어 있어요. 50개 50개로 순서대로 나누어서 훈련과 테스트 세트를 구성하면 어떨까요? AI는 세토사만 분리하는 방법만 알고 있어서 버시카라를 구분하지 못합니다. 따라서, score메서드를 통해 출력하면 정확도가 0이 나올거라는걸 어렵지 않게 예상이 가능한데요. 따라서 올바른 훈련데이터와 테스트 데이터는 골고루 섞이게 만들어야 해요. |
|
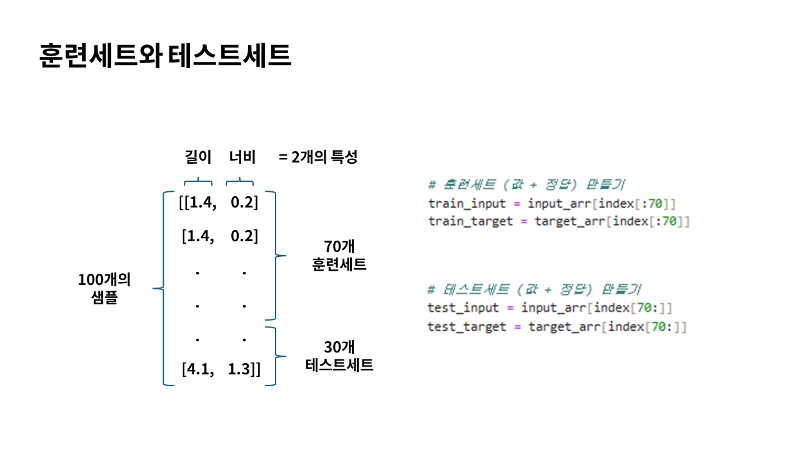
저번시간에는 파이썬 기본함수만으로 샘플을 2차원 리스트로 준비했는데요. 넘파이라는 파이썬 패키지를 이용하게 되면 이런 작업들을 손쉽게 준비가 가능합니다. 넘파이는 파이썬의 대표적인 배열을 다루는 라이브러리인데요. 넘파이는 고차원 배열을 손쉽게 만들고 조작이 가능한 도구를 많이 제공하고 있어요. 배열은 데이터를 나열한 집합인데요. 리스트와는 다르게 행렬처럼 연산이 가능하고요. 테이블, 행렬, 벡터등의 표현은 컴퓨터에서 배열로 표현하게 되는데요. 배열의 종류는 차원으로 구분하게 됩니다. 1차원 배열은 공간상에서 선을 의미하고요. 2차원 배열은 면, 3차원 배열은 공간을 나타내게 됩니다. 지난시간에 우리가 파이썬으로 만든 2차원 배열은 가로로 나열된 형태였지만 넘파이는 친절하게 우리가 보기 쉽도록 행과 열을 가지런히 출력해주게 되요. Shape 속성을 이용하면 샘플과 특성 수를 출력해주게 됩니다. |
|
파이썬 리스트를 넘파이 배열로 바꾸기는 정말 쉬운데요. 넘파이 array() 함수에 파이썬 리스트를 전달하기만 하면 됩니다. 기존에 작성했던 코드를 사용해서 iris_data 를 배열로 바꾸어 볼게요. 출력 결과를 보면 ppt처럼 보기 쉽게 배열의 차원을 구분하기 쉽게 행과 열을 가지런히 출력해주는 것을 볼 수 있죠. 눈으로 직접 보는 것 외에도 shape를 사용해서 출력을하면 샘플 수, 차원 수로도 나타내 주네요. 우리가 만든 샘플은 100개의 샘플과 2차원으로 이루어진 배열 구조임을 알 수가 있죠. |

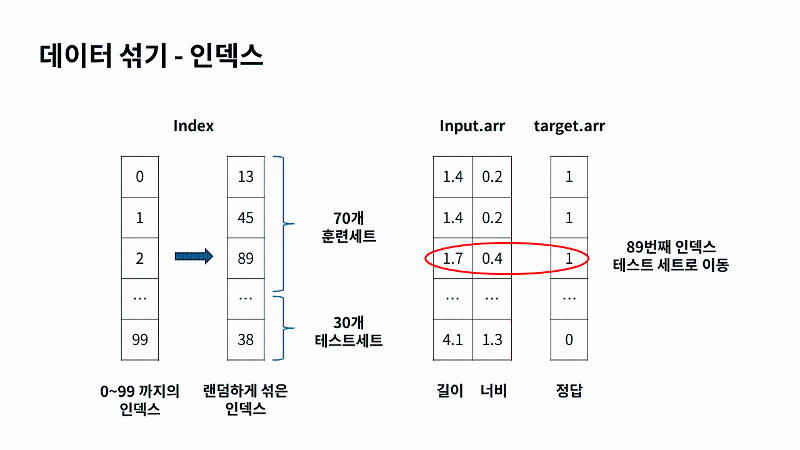
| 이제 배열을 준비했다면 이 배열에서 랜덤하게 샘플을 선택해 훈련 세트와 테스트 세트로 만들어야 하는데요. 여기에서는 배열을 섞은 후에 직접 나누기 보다는 무작위로 샘플을 골라서 사용해 볼게요. 다만 주의해야 할 점은 input 과 target에서 같은 위치는 함께 선택되어야 한다는 점인데요. 예를 들어 input_arr의 두번째 값은 훈련세트로 가고, target의 두번째 값은 테스트 세트로 가면 안 되겠죠. 지도학습 특성상 타깃 즉 정답은 함께 움직여야 합니다. 이렇게 하려면 샘플에 인덱스를 따로 생성해서 부여해 주면 되는데요. 훈련세트와 테스트 세트로 나눌 인덱스 값을 처음부터 섞어서 input_arr 과 target_arr에 부여하면 무작위로 훈련 세트와 테스트 세트를 나눌 수 있겠죠. |
|
넘파이 arrange 함수를 사용하면 0부터 99까지 1씩 증가하는 인덱스를 간단하게 만들 수 있는데요. 그 다음 넘파이 random패키지로 이 인덱스를 섞어 버리겠습니다. 참고로 저는 넘파이에서 무작위 결과를 만드는 함수들은 실행할 때마다 다른 결과를 만들기 때문에, 따라 할 때 일정한 결과를 얻기 위해 랜덤시드를 42로 지정할게요. 그리고 인덱스를 99까지 arrange로 100개를 생성하고요. 랜덤 패키지 아래에 있는 셔플 함수로 무작위로 섞겠습니다. 이대로 출력하면 같은 결과를 얻을 수 있을거에요. 비교를 위해 기존에 input_arr로 만든 배열의 0번째 행을 출력해 볼게요. 이제 넘파이 배열을 인덱스로 전달할 텐데요. 앞에서 랜덤하게 만든 index 배열의 70개를 훈련 세트로 train_input 변수를 전달할게요. 마찬가지로 정답 세트도 훈련세트와 같은 방법으로 함께 전달해주면 됩니다. 이렇게 만들어진 index의 첫번째 값은 9과 같은데요. 10번째 원소를 출력하면 처음 만든 0번째 인덱스와 같은 원소가 일치하게 출력되는 것을 볼수 있죠. 이제 나머지 30개를 테스트 세트로 앞의 훈련세트처럼 만들어 또 만들어 볼게요. |

|
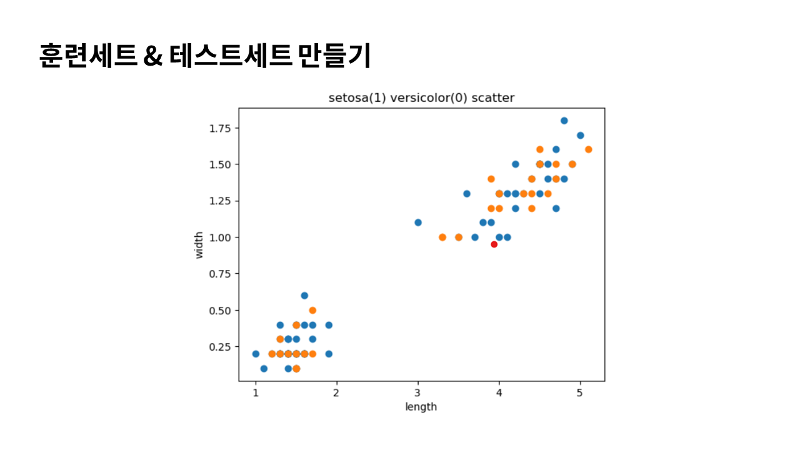
이제 모든 데이터의 준비가 끝났는데요. 훈련세트와 테스트 세트가 잘 섞였는지 그림으로 산점도로 그려볼게요. 파란색이 훈련세트고 주황색이 테스트 세트인데요. 양쪽에 세토사와 버시카라가 잘 섞인 것을 볼 수 있네요. 의도한대로 잘 만만들 진 것 같아요. 이제 모델을 다시 훈련시켜 보겠습니다. |
| K최근접이웃 모델을 다시 훈련시켜 볼건데요. .fit( ) 메서드를 실행 할 때마다, classifier 클래스의 객체는 이전에 학습한 모든 것을 잃어버립니다. 저는 이전에 만든 kn객체를 그대로 사용할게요. 훈련은 train_input과 train_target으로 모델을 훈련시키게 되는데요. 이후에 test_input과 test_target으로 이 모델을 평가하면 됩니다. 결과를 보면 100%의 정확도로 테스트세트에 있는 꽃들을 분류하네요. 직접 predict와 target을 출력해서 확인해보면 100%가 맞다는 것을 알 수 있네요. |

|
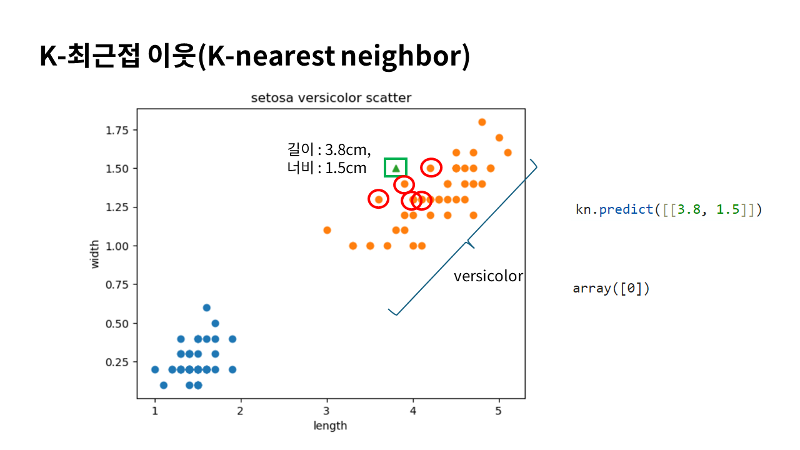
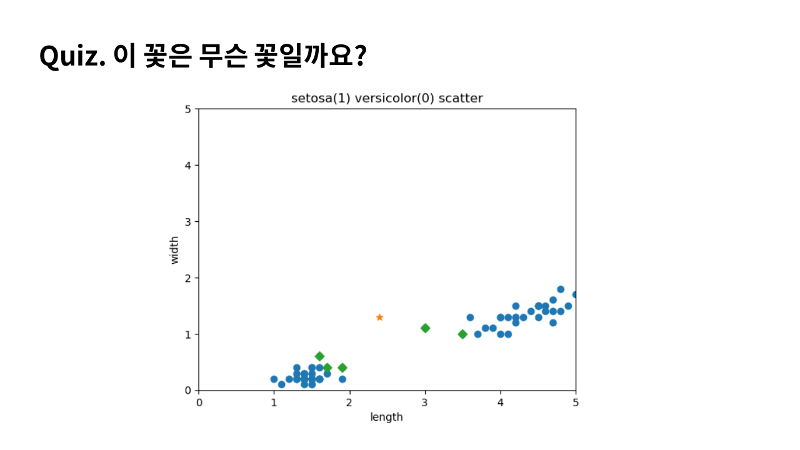
제가 문제를 하나 내보겠습니다. 사전에 제가 준비한 데이터가 아닌 새로운 데이터를 한번 AI에게 예측을 시켜보겠습니다. 길이 2.4와 너비 1.3의 새로운 샘플을 넣어 볼게요. 그래프에서 보면 버시카라에 좀 더 가까워 보이죠? 결과도 그런지 확인해보면 오히려 세토사에 더 가깝다고 분류하네요. 뭔가 좀 이상하지 않나요? 그래프에서 별표 샘플에 가장 가까운 5개의 샘플이 초록 다이아몬드로 표시되었죠. 예측 결과를 보면 버시카라에 2개 샘플만 포함되었죠. 나머지 3개는 세토사입니다. 조금 생각해보면 좌표계에서 스케일이 다른 것이 눈에 들어오는데요. 아마 이때문이 아닐까 생각해보게 되네요. 직접 거리와 이웃을 출력시켜 보겠습니다. 5개의 이웃을 거리와 indexes로 저장할게요. 직접 데이터를 타깃으로 확인해보면, 세토사라는게 확실하죠? 거리도 확인해 볼게요. 거리를 확인해보면 가장 가까운 이웃 샘플의 거리는 0.6인데 나머지는 차이가 가장가까운 샘플과 차이가 많이 나죠? 그리고 그래프에서 거리 비율도 좀 이상하네요. |
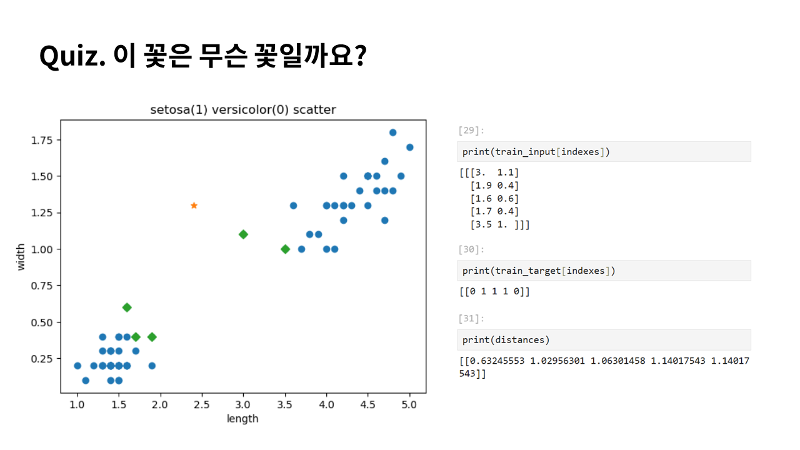
|
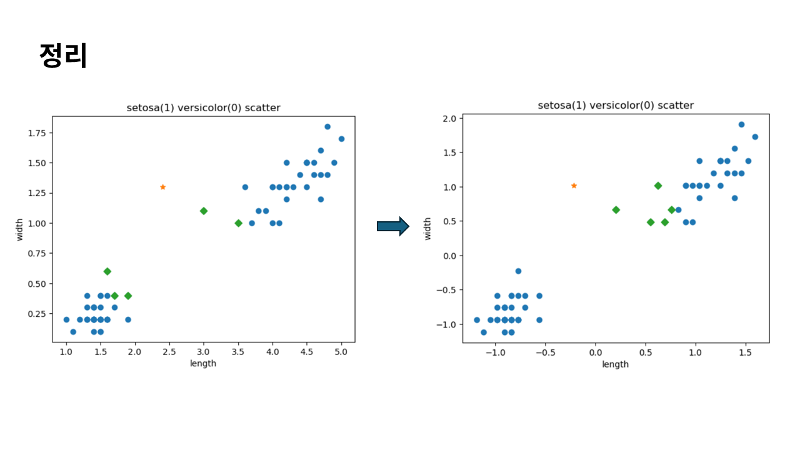
스케일을 동일하게 맞추면 x축의 거리가 더 중요하다는 것을 알 수 있죠. y축의 특성보다 x축의 특성이 더 크게 영향을 미치고 있음을 이야기 하는데요. 특성간 스케일이 다른일은 매우 흔합니다. 만약 x축의 스케일이 1만까지라면 y축의 특성은 아예 고려하지도 않을거에요. 이렇게 데이터를 표현하는 기준이 다르면 알고리즘이 옳바르게 예측할 수 없습니다. 알고리즘이 거리 기반일 때 특히 그렇습니다. 이런 알고리즘들은 샘플 간의 거리에 영향을 많이 받기 때문에 제대로 사용하려면 특성값을 일정한 기준으로 맞춰 주어야 합니다. |
|
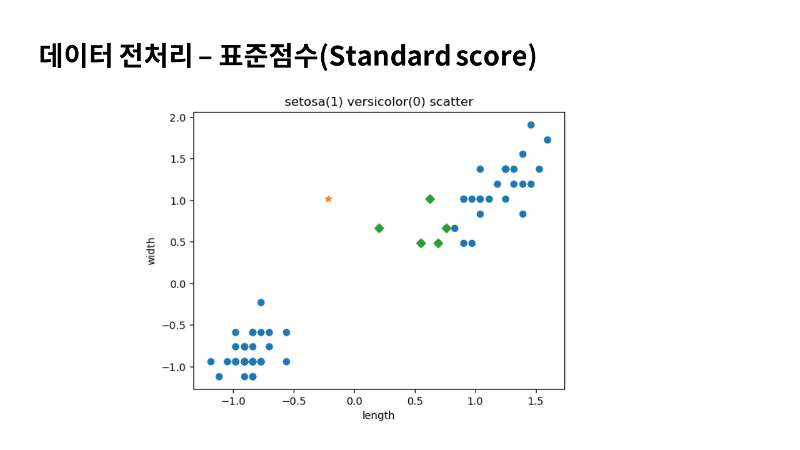
이런 작업을 데이터 전처리라고 부릅니다. 많이 사용하는 전처리 방법 중 하나로 표준점수 혹은 z 점수라고 부르는 방법이 있는데요. 표준점수는 각 특성 값이 평균에서 표준 편차의 몇 배만큼 떨어져 있는지를 나타내요. 이를 통해 실제 특성값의 크기와 상관없이 동일한 조건으로 비교할 수 있어요. 표준점수 계산(Standard score)은 넘파이를 이용하면 간단합니다. 평균을 빼고 표준 편차를 나누어 주면 되는데요. 평균과 편차는 mean과 std를 사용해요. 그리고 특성마다 값의 스케일이 다르므로 평균과 표준편차는 각 특성 별로 계산해야 해요. 이를 위해 axis=0으로 지정해야 합니다. 이렇게 하면 행을 따라 각 열의 값을 계산할 수 있어요. 이제 표준점수는 원본 데이터에서 평균을 빼고 표준편차로 나누어 표준점수로 변환이 가능합니다. 이렇게 train_input에 대해 훈련세트와 예측할 새로운 샘플을 표준점수로 변환시킬게요. |

|
그리고 산점도로 그려서 확인해 보겠습니다. 앞서 표준점수로 변환하기 전의 산점도와 형태는 거의 유사한데요. 달라진 점은 x축과 y축의 범위만 바뀌었죠. 한번 이렇게 전처리한 데이터를 다시 k최근접이웃으로 훈련시켜 보겠습니다. Kn.fit함수로 train_scaled와 정답인 train_target을 먼저 넣어줄게요. 테스트할 데이터도 표준점수로 변환 후에 score로 평가해 보겠습니다. 역시나 완벽하네요. 모든 테스트 세트의 샘플을 완벽하게 분류했다는 것이겠죠. 그럼 제가 제시한 새로운 데이터도 예측을 수행해 볼게요. 처음 내놓은 결과와 같은지 한번 확인해 볼게요. |
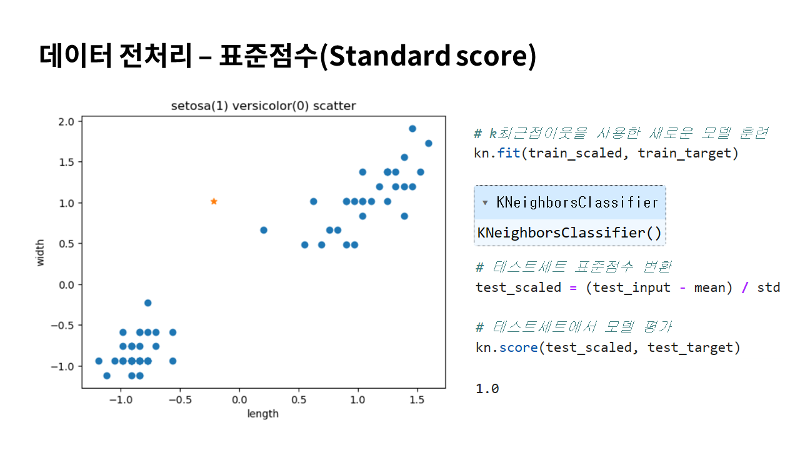
|
결과가 완전히 달라졌죠. 처음 우리가 그래프를 보고 버시카라로 예측했던 대로 결과가 나왔습니다. 이전처럼 거리와 인덱스를 사용해서 이웃을 확인해 볼게요. |
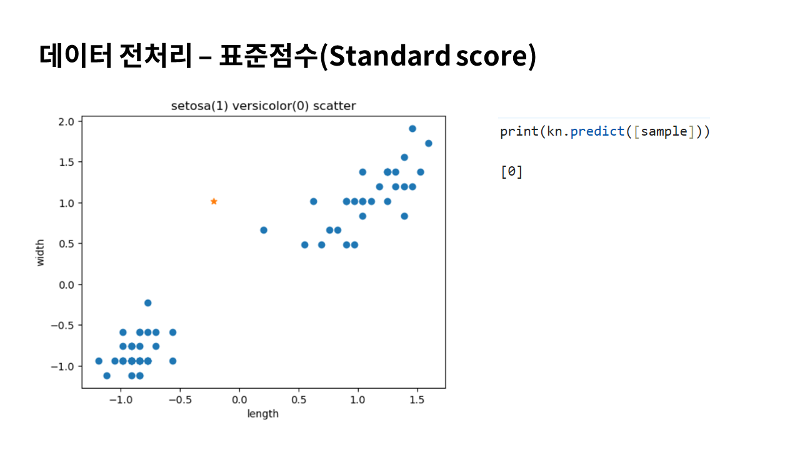
| 가까운 샘플은 모두 버시카라네요. 따라서 이 샘플을 버시카라로 예측하는 것이 당연하겠죠. 우리는 특성값의 스케일에 민감하지 않고 안정적인 예측을 할 수 있는 모델을 만들었습니다. |
|
오늘 내용을 한번 정리해 볼게요. 기존에 만든 모델은 가지고 있는 데이터를 모두 훈련시켜서 결과를 확인했습니다. 논리적으로 문제가 있어서 인덱스를 이용해서 훈련세트와 테스트세트로 구분해 주었습니다. 그런데 제가 제시한 새로운 샘플에서 그래프에서 이상하게 버시카라에 가깝지만 엉뚱하게 예측했죠. 이는 두 특성인 길이와 너비의 스케일이 다르기 때문에 발생한 문제입니다. 그래서 이를 해결하기 위해 특성을 표준점수로 변환했습니다. 이렇게 전처리를 통해 기존 모델을 개선하는 방법을 배웠습니다. |