[김건우] [AI 기초] 3. Pandas & 데이터준비 part1
작성자 : 김건우
(2024-03-18)
조회수 : 11427
[YOUTUBE] [김건우][AI 기초] [1/2] 왜 엑셀이 아닌 파이썬을 써야할까? - Pandas 데이터프레임과 전처리 (youtube.com)
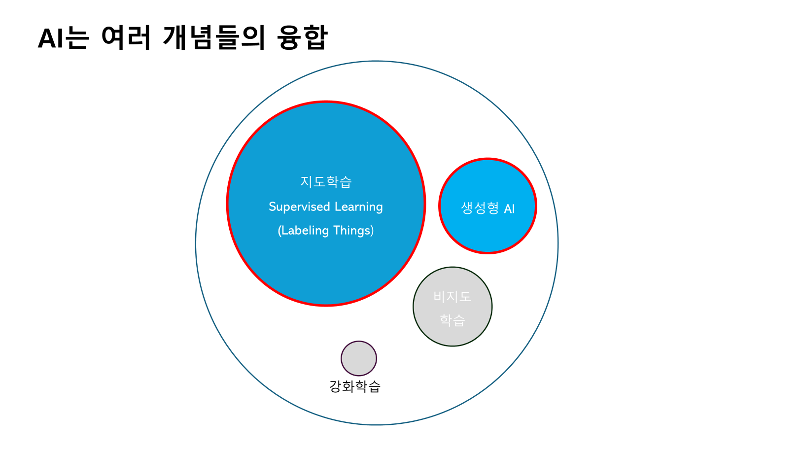
| 첫 시간에 AI는 여러 개념의 종합 세트라고 이야기를 드렸었죠. 저희는 가장 많이 사용되는 분야인 생성형 AI를 이용한 지도학습을 배우기로 했습니다. |
|
생성형 AI는 구글 바드, 쳇-GPT, 그리고 MS의 코파일럿이 대표적이죠. 이런 멋진 AI들도 사실은 지도학습을 기반으로 만들어졌는데요. 지도학습은 선생님이 학생에게 정답을 알려주면서 학습하는 방식입니다. 그리고 선생님이 알려준대로 답을 산출하는데요. 이렇게 만들어진 AI는 사물을 분류하고, 인풋을 통해 아웃풋을 산출하는 것을 잘합니다. A라는 인풋이 주어지면 B라는 아웃풋이 나올거라고 예측도 잘합니다. 이세돌을 이긴 알파고도 지도학습이구요. 우리에게 많이 노출되는 유튜브 영상 도 지도학습 기반으로 추천영상을 보여줍니다. 또 앞으로 배우겠지만, 많은 데이터가 있어야만 좋은 AI가 된다고 흔히 생각하는데요. 그렇지 않습니다. 만약 우리가 AI를 조금만 배워서 활용한다면 생각보다 많은걸 할 수 있는데요. 조그만 식당을 하더라도 식당에서 손님들이 계절이나, 날씨별로 많이 찾는 메뉴를 AI가 추천해줘서 손님이 많이 오도록 할 수도 있구요. 인터넷 쇼핑몰에서는 우리 키와 몸무게를 입력하면 옷 사진만 보고 옷이 큰지 작은지도 알려줄 수 있을거에요. 더 나아가서 우리가 옷을 입은 사진을 메타버스에서 구현해 줄 수도 있을겁니다. 우리 전공인 스마트 인프라공학에서는 어떨까요? 지진이 오기전에 계측기 정보를 보고 미리 알려줄 수도 있겠죠. 혹은 어느 지역이 제일 위험한지도 알려줄 수 있을겁니다. 이렇게 AI가 활용될 수 있는 분야는 너무나 많습니다. |
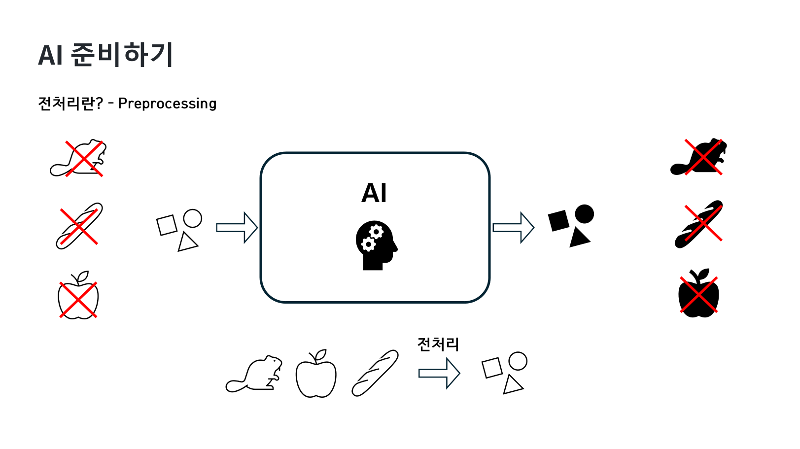

|
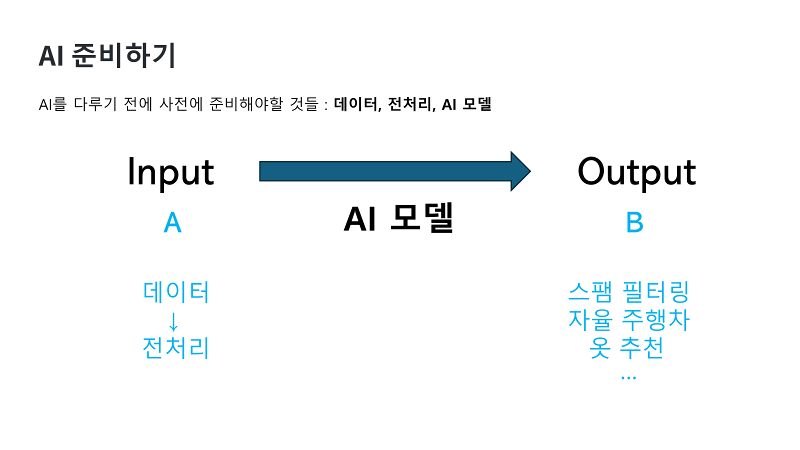
하지만 이렇게 좋은 AI가 만능은 아닙니다. 좋은 데이터를 통해 학습해야 성능이 올라가게 되고요. 아무거나 막 주면 받아들일 수 없습니다. 우리 생각보다 바보 같은 구석이 있는데요. 그림처럼 동그라미, 세모, 네모를 넣으면 색칠을 해주는 AI가 있다고 해볼게요. 이 AI는 동그라미, 세모, 네모만 색칠하는 법을 배웠기 때문에 생쥐나, 바게트, 사과를 주면 색칠할 줄 모릅니다. 때문에 사과를 색칠하고 싶으면 동그라미나 세모, 네모로 바꿔서 줘야 됩니다. 이과정을 우리는 전처리라고 부릅니다. 마치 우리가 파일이 너무 커서 압축파일로 만드는 것 같이요. 사실 전처리란게 쉬운 과정은 아닙니다. 데이터를 선별해야 되고, 정리하고, 축소하고, 변형하고, 보강하고, 유효한지도 따져 봐야 되는 다소 복잡한 과정입니다. 전통적으로 데이터 마이닝이라는 분야에서 많이 다뤄졌지만, 더 정확한 결과를 얻기 위해서 AI에도 중요하게 적용이되고 있어요. 하지만 우리가 다룰 데이터는 이미 검증된 좋은 데이터로 AI를 다루기 때문에 전처리는 다루지 않을 겁니다.
우리는 앞으로 AI를 배우는데 iris라는 데이터를 사용할 텐데요. Iris는 붓꽃이라는 이름의 꽃이에요. 필요한 데이터와 준비 과정은 유튜브 영상을 통해 설명하고 있습니다.
|
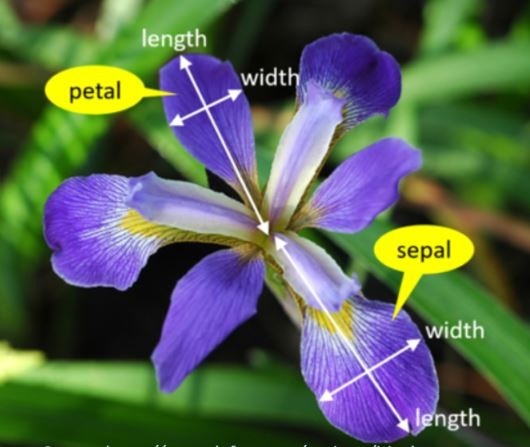
Sepal: 꽃 받침
Petal: 꽃 잎
|
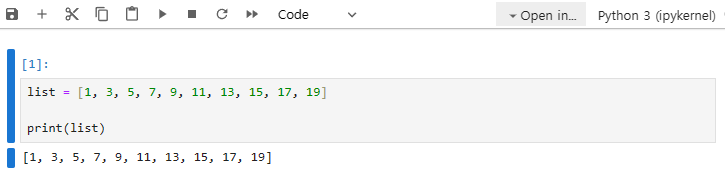
[YOUTUBE] [김건우][AI 기초] [1/2] 왜 엑셀이 아닌 파이썬을 써야할까? - Pandas 데이터프레임과 전처리 (youtube.com) 3분13초~7분27초 AI를 계속 다루게 되면 파이썬을 많이 사용하고 데이터도 파이썬으로 전처리 과정을 주로 하게 될텐데요. 첫 시간에 이야기했듯이, 보통 AI를 학습시키는데 입력되는 데이터쌍은 수만개에서 수십만개 까지는 기본적으로 들어가요. 그래서 절대 복잡한 과정을 엑셀로는 처리를 할 수가 없어요. 그렇다면 이런 어마무시한 데이터들은 어떻게 다뤄야 할까요? 작개 쪼개고 싶어도 엑셀처럼 실행도 불가능 하다면 쪼갤수도 없을거에요. 일반적으로 이런 데이터들은 엑셀보다 비교적 ‘R’ 이나 ‘SAS’ 또는 ‘Python’같은 프로그램을 통해서 다루어야 해요. 또 최대한 가볍게 데이터만 보아야 하기 때문에 파일 확장자도 엑셀파일이 아닌 csv를 주로 사용해요. 우리는 python을 다루고 있으니까 파이썬으로 다뤄봐야겠죠? 그리고 ‘R’이나 ‘sas’같은 패키지는 파이썬보다 사용자도 적고 파이썬 같은 프로그래밍 언어이기 때문에 또 배워야 해요. 굳이 파이썬을 할 수 있는데 R이나 sas같은 프로그램을 지금 다룰 필요는 없겠죠? 저희는 데이터 분석이나 처리를 위해서 파이썬의 판다스를 사용할텐데요. 판다스라는 것은 관계형이나 레이블이 된 데이터를 쉽고 직관적으로 작업할 수 있도록 설계된 Python 패키지입니다. 때문에 빠르고, 유연한 데이터 구조로 엑셀보다 무거운 데이터도 가볍게 편집하고 분석이 가능합니다. 본격적으로 판다스를 통해 데이터 편집을 하기 전에 이번주에는 용어와 개념을 다루고 가겠습니다. 리스트, List • 파이썬의 자료구조 형태 중 하나 • 순서가 있는 수정 가능한 집합 • 대괄호 [ ]로 작성되며, 리스트 내부의 값은 콤마( , )로 구분 먼저 자료형 데이터라는 것을 보고 갈게요. 대괄호 안에 숫자가 콤마로 구분되서 총 10개의 홀수를 1부터 작성해보겠습니다. 이를 리스트라는 변수로 지정해 볼게요. 리스트라는 변수를 프린트 함수를 통해 출력하면 사전에 정의한 대로 출력되는 것을 볼수 있죠. 보이는 것처럼 1차원 행렬형태로 데이터를 순서대로 나열한 것을 우리는 리스트라고 합니다. 리스트 자체는 사칙 연산을 수행할 수 없습니다. 행렬과의 차 |
|
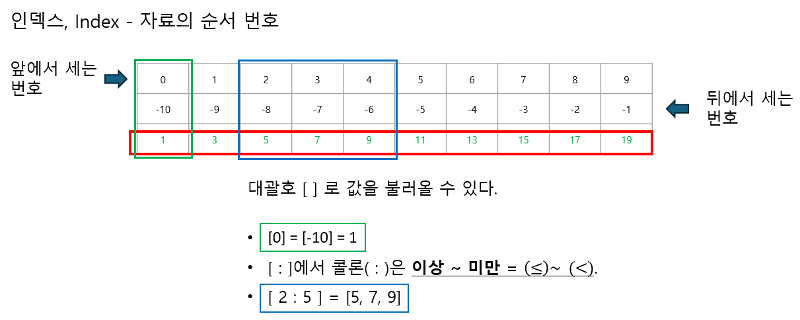
리스트에 저장된 데이터를 불러오려면 어떻게 해야할까요? 임의의 번호를 매겨서 번호를 부르면 해당하는 순번의 요소를 불러올 수 있겠죠. 우리는 이를 인덱스라고 합니다. 출석번호나 학번을 지정해서 누구를 부르는 것 처럼요. 다만 컴퓨터는 1부터 세지 않습니다. 0부터 시작해요. 인덱스에는 앞에서 세는 번호와 뒤에서 세는 번호가 있어요. 뒤에서부터 셀때는 마이너스를 붙입니다. 그래서 맨뒷자리 숫자인 19를 부를때는 9번을 불러도 되고, -1을 불러도 19가 나오겠죠. 인덱스, Index • 순서가 있는 자료형(시퀀스)에서 각 요소의 위치를 나타내는 정수 • 요소를 구별하기 위한 고유 번호 |

| 범위를 셀때는 어떻게 셀까요? 3번부터 5번을 불르려면요 2콜론 5를 씁니다. 콜론은 앞숫자 이상 뒷숫자 미만을 나타내는거에요. 그래서 3이상 6미만을 불러야 7, 9, 11이 나올겁니다. 다만 앞에서 셀때는 0부터 세니까 2이상 5미만을 불러야겠죠. |