[김건우][AI 기초] 5. chat-GPT와 함께하는 데이터시각화 - 파이썬 matplotlib
작성자 : 김건우
(2024-03-31)
조회수 : 198
|
[YOUTUBE] [김건우][AI 기초] chat-GPT와 함께하는 데이터시각화 - 파이썬 matplotlib - YouTube [CODE] 유튜브 영상 하단 설명란 |
|
이번시간에는 데이터시각화를 주제로 파이썬을 이용해서 다양한 그래프를 그려보고 기능에 대해 설명하는 시간을 갖도록 하겠습니다. 지난 영상에서 데이터를 받아서 표로 나타내 보았죠. 이후에 엑셀로 분산 그래프를 통해 점을 찍어 보기도 했었는데요. 꽃 사진으로 구분하기 힘든 것을 데이터 시각화란 것을 통해 쉽게 구분이 가능했었죠. 시각화라는 것은 우리가 데이터를 이해하고 받아들이는데 굉장히 중요한 역할을 하는데요. 때로는 하나의 좋은 그래프를 그리는 것이 백마디의 말보다 훨씬 더 효과를 발휘할 때도 종종 있습니다. 그래프를 그리는 방법은 너무나도 많기 때문에 전체를 다루기는 어렵습니다. 그래도 가장 기본적이고 앞으로 AI를 공부할 때 도움이 될 수 있는 기초적인 중요한 정보를 명확히 알려드릴 수 있도록 노력했으니 참고 해주시면 좋겠습니다. 그래서 산점도, 히스토그램, 선그래프에 대해서만 다뤄보려고 합니다. |

|
우리가 파이썬에서 그래프를 그릴때는 좋은 패키지들이 있는데요. 가장 기본이 되는게 matplotlib입니다. 그래서 numpy나 pandas같이 파이썬의 대표 과학패키지로 언급이 되구요. pandas에도 사실 그래프를 그리는 기능이 있는데요. 내부적으로는 matplotlib을 사용하게 됩니다. 물론 matplotlib위에도 더 화려하고 좋은 그래프를 나타내는데 다른 패키지들이 있다는 것 기억해주시면 좋겠습니다. matplotlib은 줄여서 plt라고 많이 사용하게 됩니다. 마치 넘파이를 np로 줄이고 판다스를 pd로 줄이는 것처럼요. |

|
산점도라는 것은 scatter plot이라고도 하는데요. 점으로 포인터로 데이터를 찍어서 그리는 그래프입니다. 주로 2차원으로 그리고요. 3차원으로도 그릴수 있지만, 좀 어렵고 한눈에 알아보기 힘들기 때문에 2차원으로 그리게 됩니다. 우리가 plt.scatter라는 함수를 호출하면 산점도를 그릴수 있는데요. 첫번째 파라미터에 x축의 값을 이야기하고요. 두번째 파라미터에 y축의 값을 나열하게 됩니다. 그래서 1,1 2,2 3,3의 값을 입력을하면 밑의 그림처럼 점이 찍히게 되겠죠. 이게 산점도입니다. 굉장히 간단하죠. |
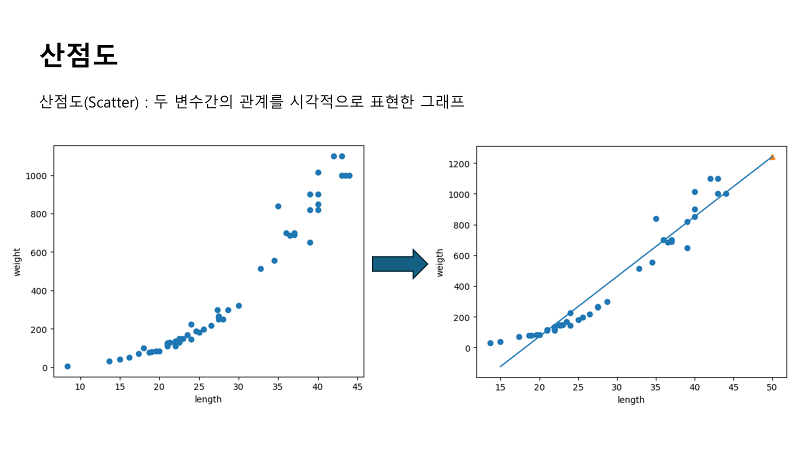
| 그리고 산점도를 활용하면 두 변수 간의 상관관계를 파악하는데 용이합니다. 수학적으로 x축에는 독립변수를 놓게되고요. y축은 다른변수로 종속변수가 됩니다. 추후에 AI를 사용할 때 선형회귀분석을 통한 데이터를 예측하는데 산점도를 많이 활용할 거에요 |
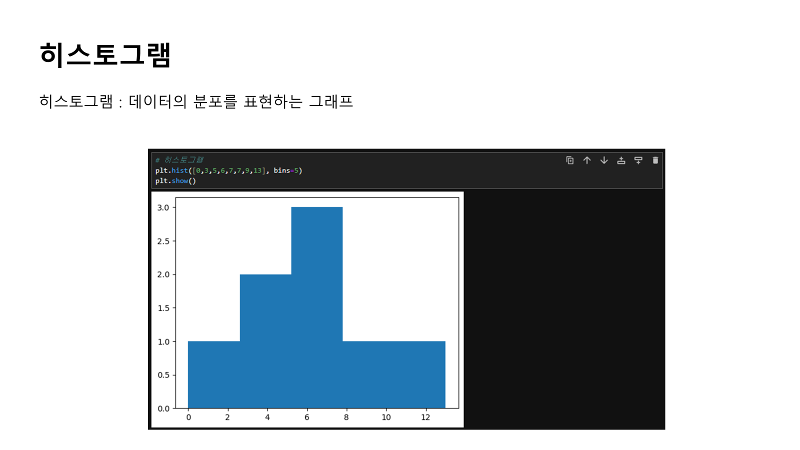
| 두 번째 그림은 히스토그램인데요. 히스토그램은 우리가 지나가다가 무심코 많이 보셨을 것 같아요. 뉴스에서도 통계 데이터를 발표할 때 히스토그램을 종종 보여줍니다. 결국 통계적으로 데이터의 분포를 확인하기 위해서 작성하게 되는데요. x축에 데이터 값의 범위인 구간을, y축에 각 범위에 속하는 데이터의 빈도수를 놓게 됩니다. 그래서 그래프를 보면 중앙값, 최빈값과 분포형태를 파악할 수가 있는데요. 이를 보고 데이터의 대칭성이나 왜도를 알 수 있습니다. 참고는 왜도라는 것은 확률분포의 비대칭성을 나타내는 지표를 이야기해요. 활용한다면 연령별 인구 분포나, 학생들의 시험 점수 분포를 파악하는데 사용할 수 있겠네요. |
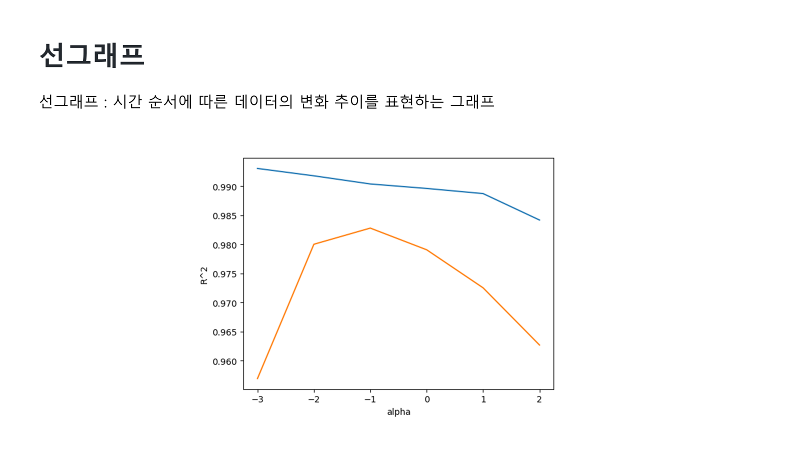
| 마지막으로 선그래프는 x축 시간 또는 순서에 따른 데이터의 변화 추이를 표현하는 그래프라고 이야기할 수 있는데요. y축의 데이터 값에 따라 각 포인트들을 선으로 연결하면 선 그래프입니다. 온도 변화 추이를 알고 싶을 때 선그래프를 사용하기도 하고요. 또는 주식 차트도 선그래프로 가격 변화를 나타내게 되죠. 이렇게 선그래프를 그리게 되면 시간에 따른 데이터 변화 추세를 파악하기가 쉬워요. 그리고 특정 시점의 데이터 값을 확인하거나 추세선을 이용한 예측이 용이해요. |
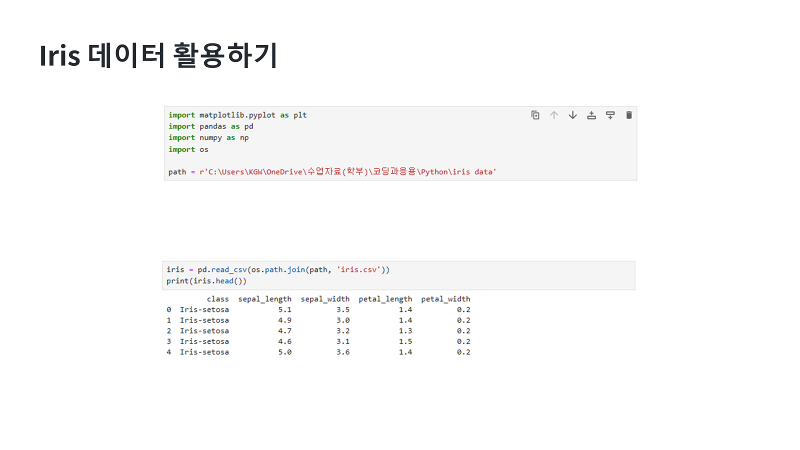
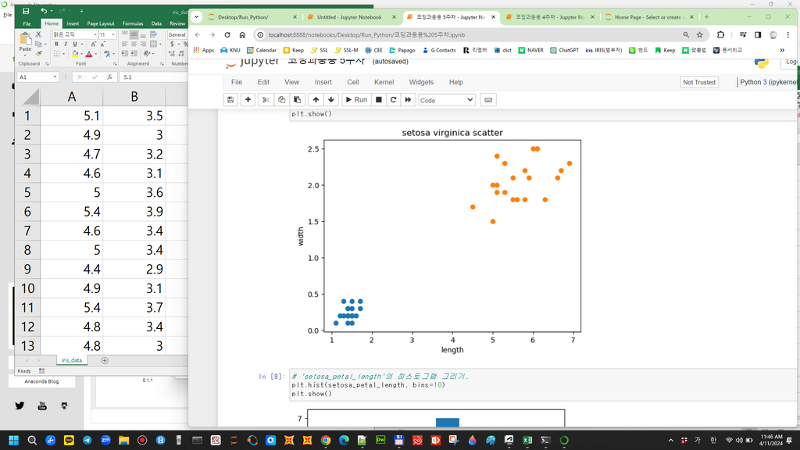
| 데이터 시각화를 이용해서 한번 지난시간에 만든 iris csv 데이터를 그래프로 출력시켜 보겠습니다. 가장 먼저 시각화를 위해서 필요한 패키지들을 불러와야 겠죠. 저번 시간에 판다스를 사용하기 위해 불러왔던 패키지에 추가로 시각화를 위한 matplotlib을 불러오면 되는데요. 이름이 길기 때문에 as plt로 불러올 수 있어요. 임포트로 matplotlib, pandas, numpy, os를 불러올게요. 저번 시간에 우리는 path경로를 지정하고 pd.read_csv함수로 csv파일을 불러오는 법을 했었는데요. 이번 시간에도 똑같이 열이름을 생성하고 수정한 데이터 파일을 불러오겠습니다. |

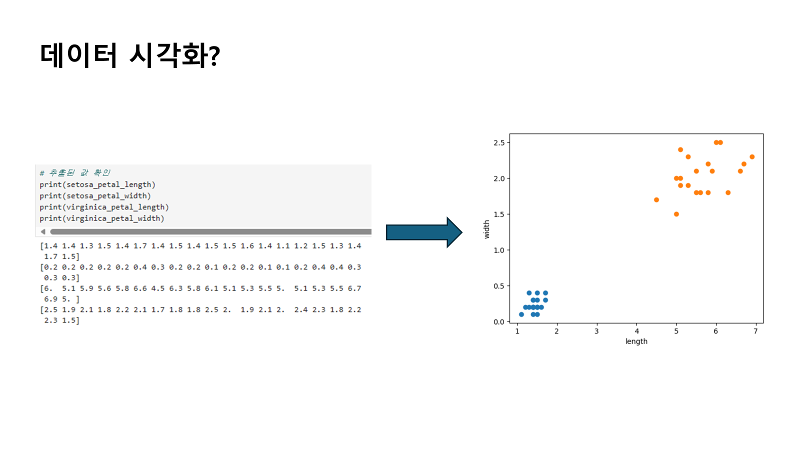
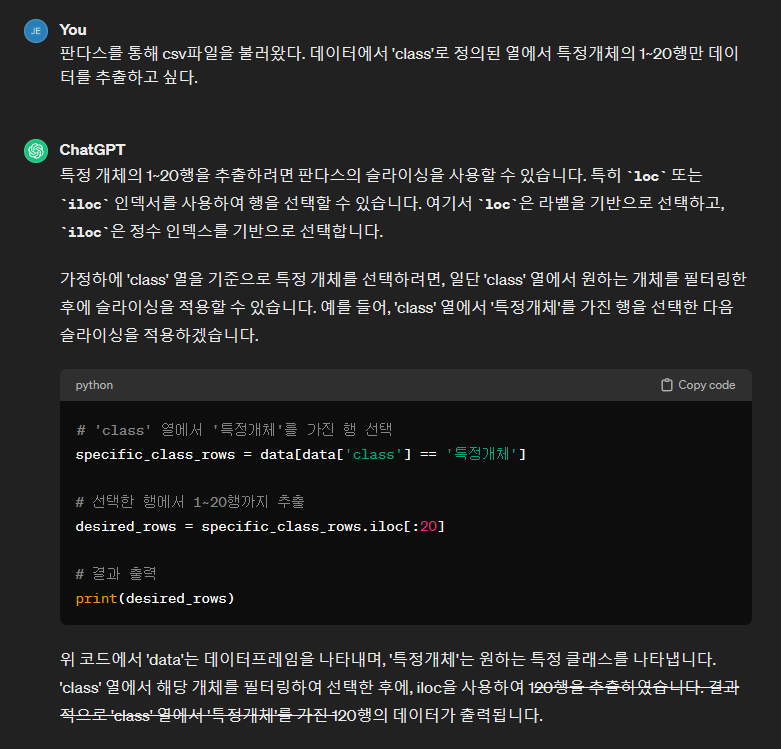
| 산점도를 그리기 위해 추출할 값으로 우리는 세토사와 버지니카의 클래스별로 꽃 잎 길이와 너비를 1행부터 20행까지 20개의 데이터를 추출하고 싶은데요. 프린트 함수와 인덱싱을 이용해서 iris데이터를 추출하고 싶은 범위로 값들을 확인할 수 있겠죠. 그런데 꽃잎 길이와 너비를 일일이 리스트로 값들을 옮겨 적기에는 너무 많아요. 그리고 pandas의 다양한 함수를 우리는 외우지 않아서 어떤 함수를 사용해야 할지 모르겠죠. 이럴 때 GPT 에게 물어보면 원하는 답변을 얻을 수 있을 것 같아요. |
|
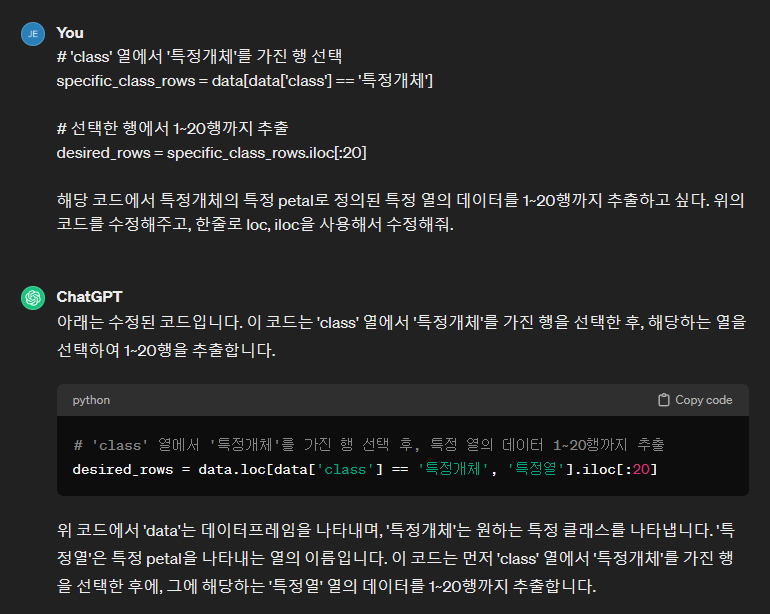
gpt에게 판다스로 csv를 불러왔는데, 원하는 열에서 특정개체로 분류된 데이터를 1~20행만 데이터를 추출하고 싶다고 이야기 해볼게요. 답변으로 loc과 iloc이라는 인덱서를 사용하라고 하는데요. 여기서 첫줄의 data라고 하는 것은 변수인데요. 우리가 iris라는 변수로 데이터를 csv_read로 불러온 데이터프레임을 나타냅니다. 그리고 클래스열과 원하는 개체의 비교연산자를 이용하라고 이야기하네요. 이를 변수로 지정해두고 iloc순서 연산자로 20행까지 불러오는 방식을 이야기해주고 있네요. 저는 이를 보고 변수가 너무 많다는 생각이 들었는데요. 우리는 두 개체의 꽃잎 길이와 너비로 총 4개의 변수를 만들어 둬야합니다. 그런데 이런식으로 코딩을 하게 되면 변수가 8개나 될거에요. 아무래도 보기 쉽지 않을 것 같은데요. Loc 속성연산자는 라벨을 기반으로 한다고 설명해주고 있는데요. loc과 iloc을 한 번에 사용해서 변수와 코드를 간략하게 만들도록 다시 질문해보겠습니다. |
|
기존에 제시한 답변을 복사한 뒤 프롬프트에 붙여 넣을게요. 이후에 원하는 대로 수정하도록 질문을 해보겠습니다. 저는 불필요한 변수를 줄이고 변수 하나로 원하는 행의 petal 값을 추출하고 싶었는데요. 위의 답변에서 제시한 설명대로 loc속성연산자를 통해 인덱스 기반의 특정열을 선택한 뒤, iloc순서 연산자를 이용해 범위를 지정하면 한줄로 줄일 수 있을 것 같습니다. 라벨로 버지니카, iloc으로 정수 인덱스 범위를 선택할 수 있을거에요. 이를 사전에 염두하고 한줄로 코드를 수정해달라고 질문해 볼게요. 답변을 보면, 수정된 코드로 기존과 조금 다르게 loc속성자을 통해 class 열의 ‘특정개체’로 비교 연사자를 통해 선택한다고 하네요. 그리고 특정열을 선택한 뒤, iloc으로 20행까지 인덱싱 하는 코드를 확인이 가능하네요. |
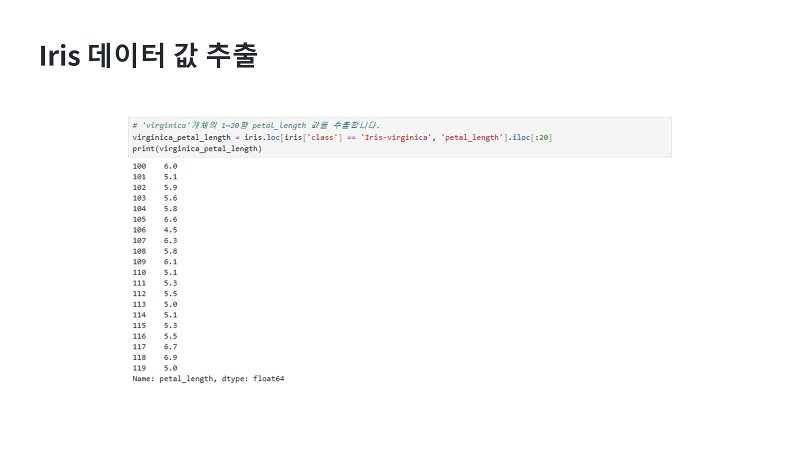
| GPT 가 답변해준대로 코드를 사용해보겠습니다. Iris로 데이터프레임을 불러왔기 때문에 GPT 답변의 data는 iris 로, ‘특정개체’ 에는 ‘Iris-virginica’로, ‘특정열’에는 ‘petal_length’로 수정할게요. 이때 대문자와 소문자를 주의해야 하는데요. 데이터프레임에 맞춰주어야 합니다. 프린트 함수를 통해 출력해 보면요, 인덱스를 포함해서 사전에 출력한 판다스에서 잘라낸 것 같은 모습을 보여주네요. 이대로 데이터 값들을 가공하고 수정할 수 있다면 너무 좋겠지만, 사실 이상태로는 그대로 사용할 수 없습니다. 저번 영상에서 배웠던 리스트를 기억하시나요? 리스트는 1차원 배열로 만들어서 저장소처럼 들고 다닐 수 있도록 하는 것이라고 이야기 드렸었죠. 데이터를 수정하고 사용하기 위해서는 이러한 리스트라는 배열 또는 저장소가 필요합니다. 그래야 오류 없이 원하는대로 가공이 가능해요. 리스트배열로 변환하는 방법은 여러가지가 있지만, 저는 numpy 패키지를 이용해서 numpy패키지로 이 숫자들을 보내버리겠습니다. 이렇게 하면 자동으로 numpy에서 리스트로 변환시켜 줍니다. |
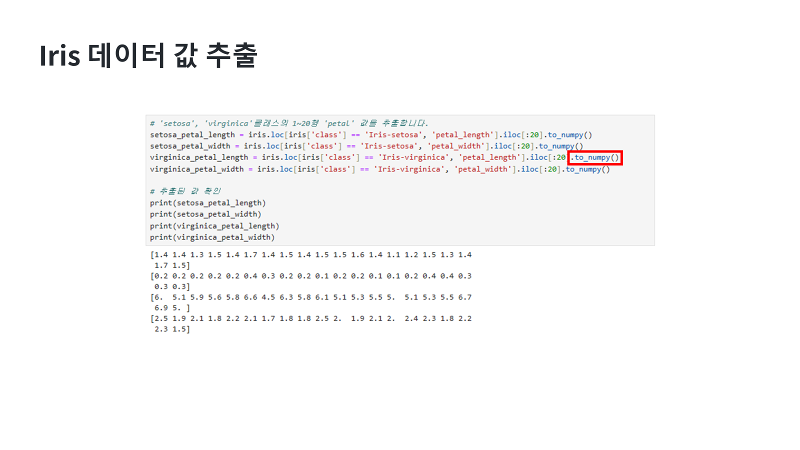
| 버지니카를 포함해서 이제 기존 계획대로 세토사까지 각각 꽃잎 길이와 너비로 4개 데이터를 추출할게요. 넘파이로 변환은 “도트 더하기 to_numpy”를 이용해 보내줄 수 있습니다. 뒤에 괄호까지 입력해야 리스트로 변환시켜 주기 때문에 괄호까지 입력할게요. 이렇게 변환한 데이터를 프린트 함수로 출력하게 되면, 대괄호 bracket으로 만들어진 리스트로 변환된 것을 확인할 수 있네요. |
|
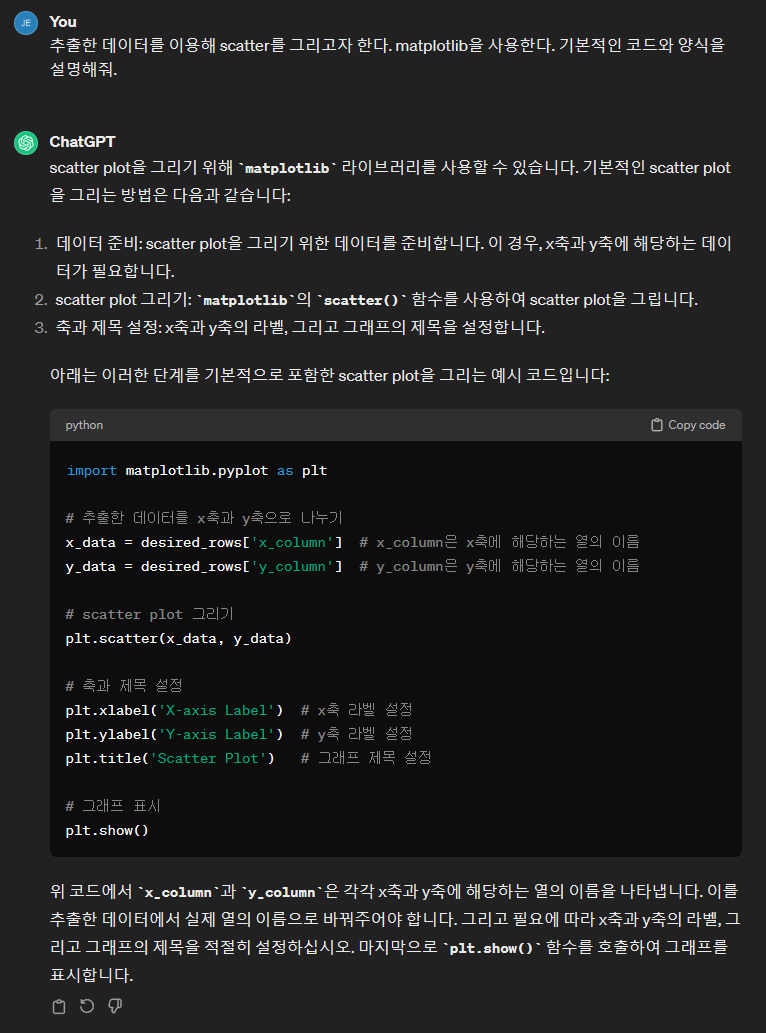
추출한 데이터를 가지고 scatter를 그려 볼 텐데요. 이번에도 어떻게 코딩을 해야 할지 막막하네요. GPT에게 코딩을 부탁해볼 게요. Matplotlob을 이용해 Scatter를 그리려면 어떻게 코드를 짜고 기본적인 양식으로 작성해 달라고 질문을 해보겠습니다. 답변으로 산점도를 그리기 위한 방법을 3단계로 걸쳐 설명을 해주고 있는데요. 라이브러리를 호출하는 방법부터 시작해서 설명을 해주고 있네요. 데이터를 준비하라고 먼저 이야기를 하고 있습니다. 참고로 GPT와 같은 생성형 AI들은 기존에 질문한 내용과 최근 질문의 전후 상황을 고려하여 답변을 하게 되는데요. 데이터 준비에 열의 이름을 내놓은 이유는 저희가 사전에 GPT 에게 클래스의 열 데이터를 추출하기 위해 질문을 했던 내용이 남아 있기 때문이에요. 그렇게 신경 쓰지 않아도 됩니다. 데이터는 리스트 형태로 제공되어야 한다는 것을 알수가 있고요. Plt.scatter 함수를 이용해서 plot을 그릴수 있다고 설명하네요. 그리고 부가적으로 축제목으로 plt.xylabel 함수를 이용한다고 하고요. 그래프 제목으로는 plt.title 을 사용한다고 합니다. 마지막으로 그래프를 프롬프트에서 출력하기 위해 흔히쓰는 print 처럼 plt.show 함수를 사용하네요. 사전에 저희는 라이브러리를 불러왔고 데이터도 준비가 되어있기 때문에 이것만 보아도 충분히 그릴 수 있을 것 같아요. |
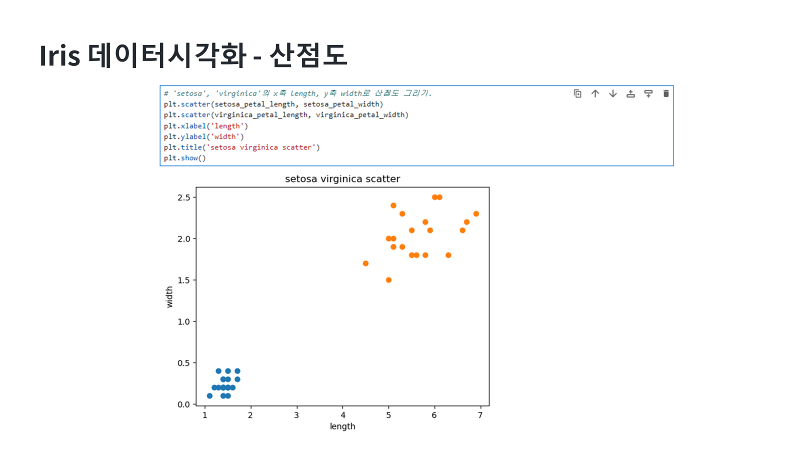
|
사전에 준비한 데이터의 length를 x축, width를 y축에 놓고 산점도를 그려볼게요. Xlabel에 length, ylabel에 width를 놓고, 세토사와 버지니카 두 데이터를 비교해 보겠습니다. 지난 영상에서 우리가 엑셀로 그렸다면, 이번에는 파이썬으로 그릴 뿐이에요. 산점도로 표현할 것이기 때문에, gpt에서 알려준대로 plt.scatter 함수를 사용할 텐데요. 괄호 안에는 x, y값이 들어갈 것이기 때문에, 먼저 저희가 사전에 지정한 변수인 ‘setosa_petal_length’ 와 ‘setosa_petal_width’를 각각 x, y값으로 지정해서 넣어 줄게요. 그리고 버지니카 데이터도 또 넣어야 겠죠. 맷플롯립은 그래프를 여러 개 넣고 출력하면 자동으로 색을 구분해 주기 때문에 특별히 본인이 원하는 색을 입히고 싶은게 아니라면, 따로 색상이나 마커 같은 파라미터를 입력하지 않아도 됩니다. 버지니카도 앞줄과 마찬가지로, plt.scatter 함수를 사용하고, 괄호안에 들어갈 파라미터로 ‘virginica_petal_length’ 와 ‘virginica_petal_width’를 각각 x, y 값으로 넣을게요. 그리고 xlabel함수 괄호안에 ( ‘ )를 넣고 length, ylabel함수 괄호 안에 ( ‘ ) width를 넣어줍니다. 그리고 타이틀함수까지 입력하면 기본적인 그래프 양식이 완성됩니다. 이렇게 설정한 plt 함수를 plt.show를 통해 출력하면 결과로 그래프가 생성되는걸 확인할 수 있어요. |




|
사실 내용이 그렇게 많지는 않지만, 시각화는 너무나 중요하고 공부할 때 그래프를 그리게 되면 보다 쉽게 이해가 가능하기 때문에 한번은 이해하고 가는것이 중요합니다. 조금전 matplotlib을 이용해 그래프를 그리기 위한 함수와 포멧들은 꼭 외워 두는게 좋습니다. 다음 영상부터는 본격적인 AI 머신러닝의 개념과 실습을 주제로 수업을 진행하겠습니다. 감사합니다. |