[김건우][AI 기초] 7. K-최근접이웃(KNN) - AI 모델 생성
작성자 : 김건우
(2024-04-25)
조회수 : 79
[YouTube] https://youtu.be/3zyK95kkdco
[Code] 코딩과응용 7주차.py [Link]
[데이터] iris_data.csv [Link]
-------------------------

 |
 |
|
저희가 머신러닝을 다룬다는 것은 프로그램을 파이썬을 통해 만든다는 뜻인데요. 이론을 다루기 보다는 직접 코딩을 통해서 이해하고 쉽게 접근을 해보면 좋겠어요. 저희는 iris라는 붓꽃을 눈으로 구분하기 어려우니 자동으로 분류를 해줄거에요. 만약 데이터에 없는 붓꽃이 들어와도 이꽃은 어떤 꽃인지 맞출 수 있어야 겠죠. 가장 쉬운 문제인 세토사와 버시카라 라는 두 종류의 붓꽃 데이터를 가지고 알아 맞히는 문제를 풀어볼게요. |
|
가장 먼저 데이터를 준비해야겠죠. 사전에 저희는 판다스를 이용해 데이터를 추출하고 가져오는 방법을 배웠는데요. 이를 산점도로 그려도 보았었죠. 기존의 코드를 조금 수정해서 리스트 형태로 데이터를 가져와 볼건데요. 저번 영상에서 만들어 둔 코드를 활용해서 import로 데이터 추출을 위한 패키지를 불러오겠습니다. |
데이터 준비하기
|
판다스의 loc과 iloc 속성자를 사용해서 리스트의 출력결과를 보면 세토사라는 붓꽃의 꽃잎 길이가와 너비가 각각 1.4cm, 0.2cm 인것을 알수가 있죠. 이러한 데이터가 총 100개의 샘플로 있다고 생각할 수 있을거에요. 혹은 샘플이 아닌 특성이라고 부를 수 있어요. |
데이터 추출


|
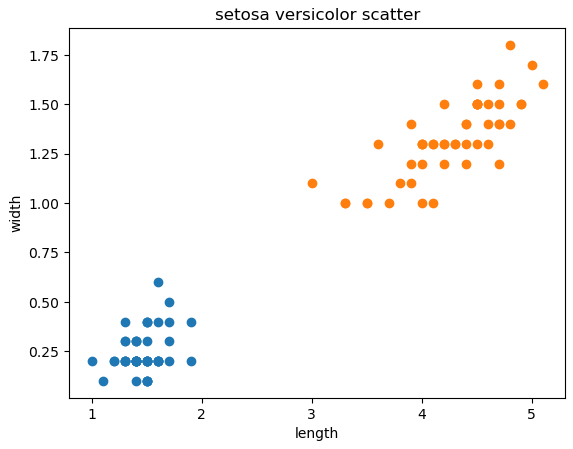
그리고 이 꽃잎 데이터들을 코드를 통해 산점도에 나타내면 그래프가 다음 사진처럼 찍히는 것을 볼수가 있죠. 길이를 x축에 놓고 너비를 y축에 넣었죠. X,y 축이 서로 바뀌어도 상관없습니다. 둘이 다르다는 것만 보면 되니까요. 확실히 버시카라가 길이와 너비가 좀 더 크다는 것을 알 수 있는데요. 저희가 이렇게 육안으로 보아도 두 데이터를 구분하는게 그렇게 어렵지 않을거라는 것을 미루어 짐작할 수 있겠네요. |
데이터 시각화

|
이렇게 데이터를 리스트로 준비를 했는데요. 한가지 더 준비를 해야할것이 있어요. 길이와 너비를 이제 하나의 파이썬 리스트로 합쳐야 되요. 왜냐하면 머신러닝 프로그램에 세토사와 버시카라 중에 하나의 데이터만 전달하면 당연히 두 붓꽃을 구분할 수 없겠죠. 그래서 모두 전달을 해주어야 하는데요. 이럴 때 두 리스트를 ‘+’연산자를 통해 만들어 주면 데이터가 합쳐져요. 그래서 저희가 덧셈을 통해 두 리스트를 합치면 하나의 리스트가 만들어 지게 됩니다. 이런걸 ‘연산자 오버로딩’이라고도 부르게 되는데요. 중요한건 아니구요. 리스트를 합치면 뒤에 붙어서 하나의 리스트로 만들어진다 라는 것만 알고 가면 좋겠어요. 이를 이용해서 세토사와 버시카라의 길이를 ‘length’로 합치구요. 마찬가지로 너비에 대해서도 ‘width’라는 변수로 합치겠습니다.
|
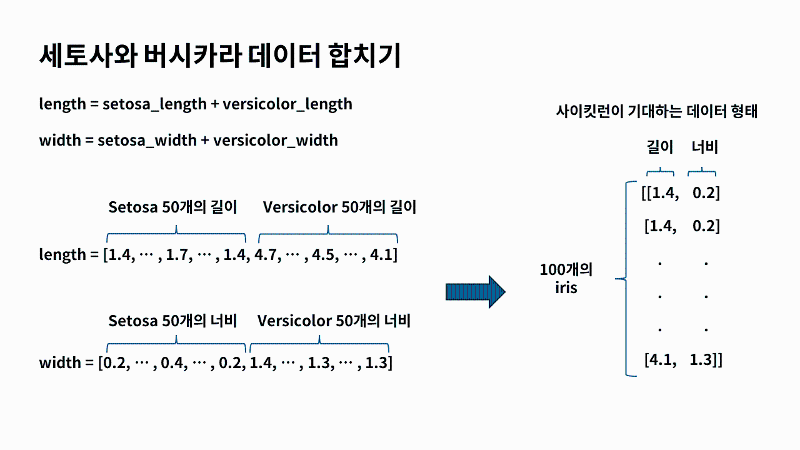
|
그래서 어떻게 하는지는 ‘리스트 내포’라는 것을 통해 한다고 이야기 할 수 있는데요. 파이썬 프로그램에서 종종 쓰이는 구문 방법중 하나에요. 저희가 대괄호 리스트를 만드는데, 리스트 안에 포문이 들어 있는 거죠. 그래서 리스트 안에 포문 같은게 들어가 있다고 해서 ‘리스트 내포’라고 많이 불러요. 그래서 앞에서 만든 ‘length’랑 ‘width’를 파이썬의 ‘zip’ 함수로 묶으면 length 리스트에서 원소하나 꺼내서 l에 넣고, width에서 원소하나 꺼내서 w에 할당하게 되는데요. 이걸 for를 통해서 계속 반복을 하는거죠. 언제까지? Length 와 width가 끝날 때 까지요. 이렇게 꺼내 놓는걸 반복을 하고 l과 w로 작은 리스트를 만들어서 큰 외곽의 리스트에 추가하게 됩니다. 그렇게 되면 밑에 있는 사진처럼 결과가 출력이 되겠죠. 아까 첫번째로 본 세토사의 1.4의 길이와 너비가 0.2인 이런 샘플이 만들어지게 될거에요. 이렇게 해서 전체 100개의 샘플을 리스트의 리스트로 만들 수 있어요. 이렇게 나온 데이터를 ‘iris_data’ 라는 변수에 저장을 했어요. 이제 저희가 2차원 배열도 준비했으니까 사이킷런을 이용해서 머신러닝을 바로 수행할 수 있는 것은 아니구요. 추가적으로 또 한가지 더 준비를 해야 해요. 준비할게 너무 많죠? |
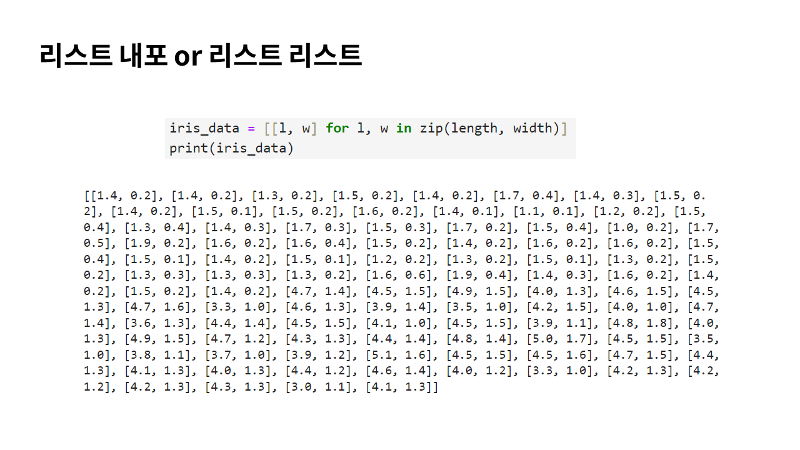
|
마지막은 정답을 준비해야 되요. 제가 지도학습에 대해서 설명드릴 때 지도학습은 선생님이 학생한테 정답을 알려주면서 학습시키는 것이라고 했었죠? 마찬가지로 우리가 준비한 데이터들의 정답을 프로그램한테 알려줘야 해요. 정답은 무엇이 될 수 있을까요? “이 데이터는 세토사고 이 데이터는 버시카라야.” 라고 알려주는 것이에요. 우리가 정답을 알려주지 않으면 AI가 구분하는 방법을 찾을 수가 없어요. 저희가 AI에게 규칙을 찾게 끔 하려고 하는데 뭔가 정답을 알려주지 않으면 규칙을 찾을 수 없는거죠. 마치 우리가 시험을 보기전에 정답이 있는 연습문제를 풀고 공부를 해서 정답을 알려주지 않는 시험을 보는것과 굉장히 비슷하죠. 그래서 데이터만 AI에게 제공을 하면 배울 수 있는게 없습니다. 그래서 문제와 데이터와 정답을 함께 줘야한다는 점 꼭 기억해 주면 좋겠습니다. 다시 돌아와서여기서도 정답을 준비할텐데요이진 분류를 위한 연산자 오버로딩이라는 것을 사용하면 간단하게 만들수 있어요하나가 들어있는 리스트가 세토사로 세토사 데이터 개수만큼 곱해주면 출력된 것 처럼이개가 늘어선 리스트를 만들수 있어요마찬가지로 버시카라를 위한이 들어있는 리스트에개를 곱해주면 이 들어있는개의 리스트가 만들어 지구요이를 더해주면 총개로 구성된 리스트를 간단하게 만들 수 있어요아주 간단하죠 |

|
우리가 사용할 머신러닝 라이브러리가 사이킷 런인데요. 다른 거의 모든 머신러닝 라이브러리는 이진 분류를 위해, 그러니까 두개의 클래스를 분류하기 위해 이런 정답을 0 아니면 1로 표시해요. 우리는 세토사를 1로 두었고 버시카라를 0으로 두었는데요. 만약에 반대로 버시카라를 찾는 문제로 바꾸고 싶다면 버시카라를 1로 놓고 세토사를 0으로 놓으면 되겠죠. 간단하죠? 이렇게 0또는 1을 얻는 것이 이진 분류다 라고 이해하면 좋겠어요. 이제 여기까지 해서 여러 데이터를 2차원 리스트로 나타냈고 훈련할 데이터를 리스트에 리스트로 준비를 했고요. 또 정답 데이터도 0과 1로 준비를 했는데요. |

|
그럼 이제 준비가 다 끝났으니 머신러닝 AI모델을 만들어 볼게요. 앞에서 너무 길게 준비를 하고 작업을 했는데요. 실제로 AI모델을 만드는 과정 자체는 너무 간단해요. 보면 가장 먼저 사용할 AI 알고리즘이 K-최근접 이웃인데요. 이 알고리즘은 굉장히 간단해요. 이해하기도 매우 쉽고 원리도 심플해요. 그래서 이번 알고리즘을 통해 AI가 생각보다 쉽다고 생각했으면 좋겠어요. 일단은 k-최근접 이웃이 뭔지 알고리즘을 설명하기 보다는 한번 적용해 보면서 조금씩 알아보도록 할게요. 사용할 싸이킷런은 ‘sklearn.neighbors’ 라는 모듈 밑에 ‘k neighbors classfier’라는 클래스로 k최근접이웃이 구현되어 있어요. 그래서 저희가 파이썬에서는 프롬 임포트라는 구문을 사용해서 클래스를 임포트 할 수가 있어요. 또 클래스를 사용할 때는 저희가 클래 이름 뒤에 괄호를 붙여서 ‘클래스의 인스턴스를 만든다.’ 아니면 ‘클래스의 객체를 만든다.’ 이렇게 표현을 하게되요. 그리고 저는 클래스 객체를 kn이라는 이름으로 저장을 했습니다. 이렇게 하면 사용할 준비가 끝난건데요 그 다음에 저희가 앞에서 만든 iris_data 그리고 iris_target 이 두 데이터를 kn 객체 핏 메소드에 전달을 하게 됩니다. 이 ‘fit’라는 메소드가 두 데이터를 가지고 머신러닝모델을 훈련하게 되는 거구요. 이때 이 fit 앞에 kn을 모델이라고 부르게 됩니다. 머신러닝 모델이겠죠? 그러니까 이렇게 머신러닝 프로그램의 알고리즘이 객체화 된 것을 모델이라고 보게 되는데요. 혹은 알고리즘 자체를 모델이라고 부르기도 해요. 그래서 문맥에 따라서 적절하게 이해하면 되겠습니다. 그리고 이 fit메소드는 k최근접 이웃에만 있는 것은 아니구요. 사이킷런 안에있는 다른 클래스들도 똑같이 fit메소드를 쓰게 되요. 그래서 사용법만 한번 익히면 다른 클래스를 호출 할 때도 굉장히 쉽게 적용이 가능한데요. 이렇게 fit 메소드를 호출하면 훈련이 끝난거에요. 아마 금방 작업이 끝날텐데요. 이 모델이 얼마나 잘 학습 했는지 알아보려면 스코어 메소드로 훈련데이터, 즉 iris_data를 가지고 정답 데이터인 iris_target에 얼만큼 잘 맞췄는지 스코어 메소드로 확인이 가능해요. 스코어 메소드를 호출하면 1.0이라고 나오는 것을 볼 수가 있는데요. 이건 100%다 맞췄다는 겁니다. 0에서 1까지의 값을 출력해주는데 1이면 100% 다 맞췄다는 것을 의미해요. 만약에 우리가 iris데이터가 100개가 있는데 100개 중에 70개만 마쳤다면, 70%인 0.7이 출력이 될거에요. 이렇게 AI가 얼마만큼의 정답을 맞췄다라는 것을 ‘정확도’라고 이야기를 합니다. 그래서 이 모델은 우리가 k최근접이웃으로 iris_data와 iris_target 으로 훈련을 했더니 100%의 정확도를 달성 했다는 것을 이야기 할 수 있습니다. |

|
이제 우리가 만든 이 kn 모델을 가지고 새로운 데이터를 넣었을 때 어떻게 동작하는지 한번 보도록 할게요. 예를 들어서 그림처럼 세모로 표시되어 있는 길이가 3.8cm에 너비가 1.5cm인 붓꽃이 있다고 해볼게요. 당연히 이건 버시카라라고 생각할 수 있는데요. 하지만 우리가 만든 모델을 가지고 한번 어떻게 분류를 하는지 직접 볼게요. 이때 사용하는 메서드가 predict 메서드 이구요. Fit와 score메서드와 마찬가지로 클래스가 kn으로 동일하게 사용을 하구요. 하지만 이때 우리가 훈련 데이터를 줄 때 2차원 리스트 형태로 제공을 했었죠. 여기서도 마찬가지로 2차원리스트로 제공을 해야하기 때문에 새로운 샘플 데이터도 리스트에 리스트로 값을 넣어 주어야 해요. 예측을 수행을 하면 결과가 0으로 나오게 되는데요. 앞에서 우리가 0은 버시카라로 지정을 했었죠. 그래서 결과를 우리가 생각한대로 일치하게 예측을 하고 있다는 것을 볼 수가 있죠. 그러면 이 k최근접 이웃이 예측하는 방식이 어떻냐면, 마치 우리가 이 그림을 보고 ‘버시카라에 가까이 있으니까 버시카라일거야’ 라고 예측한것과 굉장히 비슷하게 예측을 하는데요. 그래서 이 k최근접 이웃은 이 주위에 있는 샘플들을 보고 그 주위에 있는 샘플들이 어떤 클래스에 있는지 가장 많이 속해 있는 클래스를 정답으로 찾는거죠. 주위에 있는 샘플들은 기본값으로 5인데요. 대충 주위에 있는 5개를 골라보면 그림처럼 대충 사진처럼 있겠죠? 당연히 주위에 있는 점들은 다 버시카라이구요. 그러니까 버시카라 밖에 없으니까 이 샘플은 버시카라라고 결정을 해서 예측을 하게 되는거에요. 그래서 이름이 K neighbors죠. 주위에 이웃들을 보기때문이에요. 여기서 K는 주위의 이웃을 찾을 개수인데요. 기본값은 5입니다. 그래서 5개 주변의 샘플들을 보고 그 주변 샘플의 클래스중 가장 많이 속해있는 클래스를 정답클래스로 찾습니다. 예를 들어서 5개중 2개가 세토사고 3개가 버시카라면 정답으로 버시카라를 찾겠죠. 굉장히 심플하죠. 알고리즘 치고는 별 것 없는데요. 사실 AI는 데이터를 학습할 때 패턴을 학습하는 것을 목표로 하는데요. 오늘 만든 k최근접 이웃만 보면 뭔가 규칙을 학습한 것처럼 보이진 않죠. 그래서 k최근접 이웃은 굉장히 단순한 알고리즘입니다. 하지만 이후에 나올 다른 알고리즘을 보면 규칙을 찾는구나라고 확실이 느낄 수 있을거에요. |
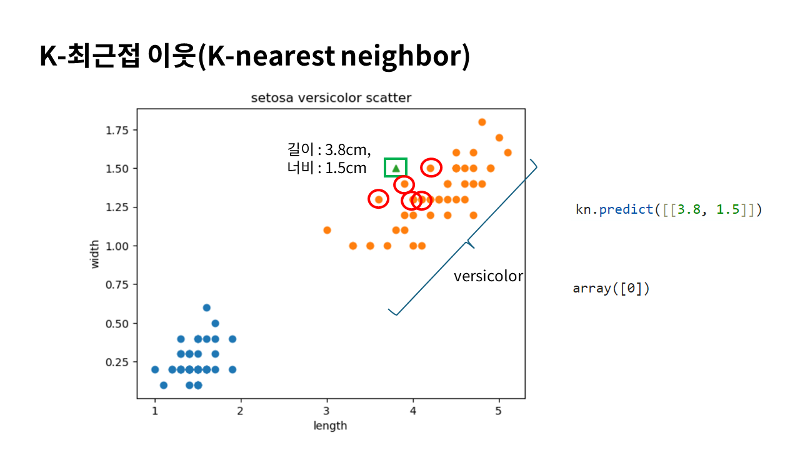
|
그리고 우리가 한번 생각해 보아야 할 것은 k최근접이웃에 대해서 자세히 알아보진 않았지만 이 알고리즘이 어떻게 구현되어 있는지 직접 이해하고 짠 것이 아니죠. 이미 짜여있는 싸이킷런의 클래스를 이용해서 구현한 것 뿐이에요. 싸이킷 런 내의 다른 머신러닝 클래스들이나 나중에 배울 파이토치 같은 그런 기능들도 마찬가지에요. 저희가 직접 알고리즘을 구현하는건 아니구요. 그런일을 하는 사람도 있지만 저희는 구현된 라이브러리를 이용해서 원하는 목적에 맞게끔 사용하는 일을 주로 하게 될거에요. 다음 시간에는 k최근접이웃을 이용해서 좀 더 정교하게 AI를 다루어 보겠습니다. 감사합니다 |