[김건우][AI 기초] 6. 머신러닝의 개념 & 분류와 회귀 그리고 예측
작성자 : 김건우
(2024-04-17)
조회수 : 75
| [YOUTUBE] [김건우][AI 기초] 머신러닝이란 무엇일까요? - 분류 & 회귀 / AI 공부와 활용법 (youtube.com) |
|
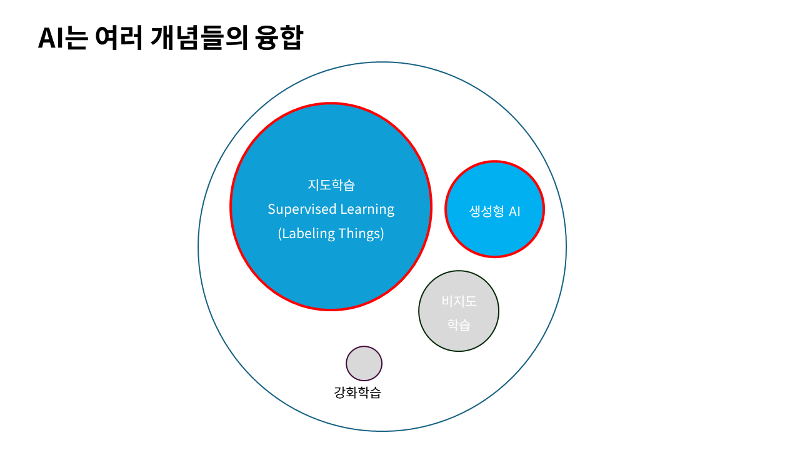
AI를 다루기 위해 기본적인 AI의 개념과 정의 그리고 알고리즘 사용을 위한 분류와 회귀에 대해 설명하고자 합니다. 첫 시간에 AI는 여러 개념의 종합 세트라고 이야기를 드렸었죠. 저희는 가장 많이 사용되고 활용되는 분야인 지도학습을 생성형 AI를 이용해 배우기로 했습니다.
|
|
지도학습은 선생님이 학생에게 정답을 알려주면서 학습하는 방식이라고도 이야기 했었죠. 그리고 선생님이 알려준 대로만 답을 산출하죠. 이렇게 만들어진 AI는 사물을 분류하고, 인풋을 통해 아웃풋을 산출하는 것을 잘합니다. A라는 인풋이 주어지면 B라는 아웃풋이 나올 거라고 예측(Prediction)도 할 수 있어요. 이러한 지도학습을 우리는 다루는데요. 지도학습에는 분류와 회귀 그리고 예측이 있습니다. 머신러닝을 통해 이를 다루게 될거에요.
|

|
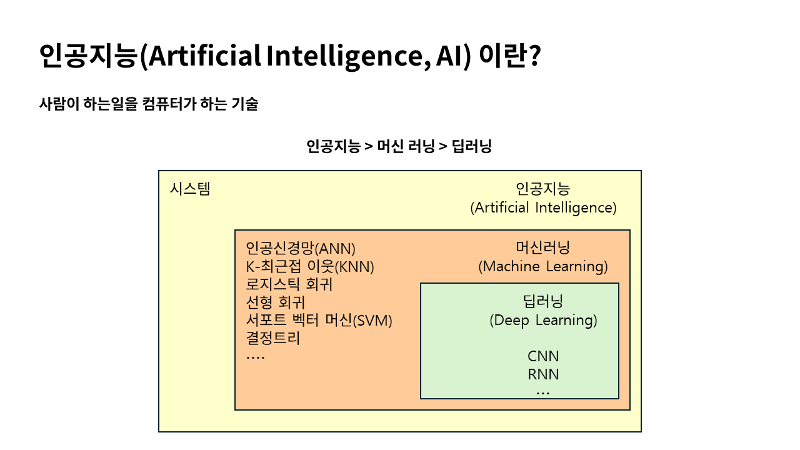
머신러닝이 뭔지 알기 전에 인공지능이 뭔지 정확히 알아야 하겠죠. AI, 인공지능은 인간의 지능을 모방하여 사람이 하는 일을 컴퓨터가 할 수 있도록 하는 기술을 AI라고 정의합니다. 이러한 AI를 구현하는 방법으로 머신러닝과 딥러닝이 있습니다. 인공지능에서 머신러닝과 딥러닝은 그림처럼 관계를 정의하게 되는데요. 목적과 환경에 맞도록 데이터를 분석하기 위해서는 이러한 관계와 차이를 명확하게 이해해야 해요. 머신러닝과 딥러닝 모두 학습 모델을 제공하고 데이터를 분류할 수 있는 기술이에요. 하지만 접근 방식의 차이가 있는데요. 머신러닝의 가장 큰 특징은 주어진 데이터를 사람이 먼저 전처리를 해야 해요. 그러니까 데이터를 컴퓨터가 인식할 수 있도록 사전에 준비할 필요가 있다는 이야기입니다. 반면 딥러닝은 기존에 사람이 하는 전처리와 같은 작업을 모두 컴퓨터가 하도록 할 수 있습니다. 대량의 데이터를 컴퓨터에게 줘버리면 스스로 분석하고 학습해서 정답을 찾아내는 것을 이야기 하는겁니다. 우리는 먼저 머신러닝부터 다루어 볼거에요.
|
|
머신러닝은 요컨데 우리가 직접 수많은 규칙을 미리 정해주는 대신 프로그램 자체가 데이터를 통해 스스로 학습하도록 하는 방법을 이야기합니다. 머신러닝 자체는 굉장히 오래된 개념이에요. Arthur Samuel은 1959년에 machine learning을 “컴퓨터에 명시적으로 프로그래밍하지 않고도 학습할 수 있는 능력을 부여하는 학문 분야” (“Field of study that gives computers the ability to learn without being explicitly programmed.”) 로 정의하고 있어요. 하지만 최근에 AI가 많은 연구를 거치면서 기법이나 방법론이 비약적으로 발전했고, 이제는 어디든 써먹을 수 있는 기능으로 받아들여 지고 있어요.
|

|
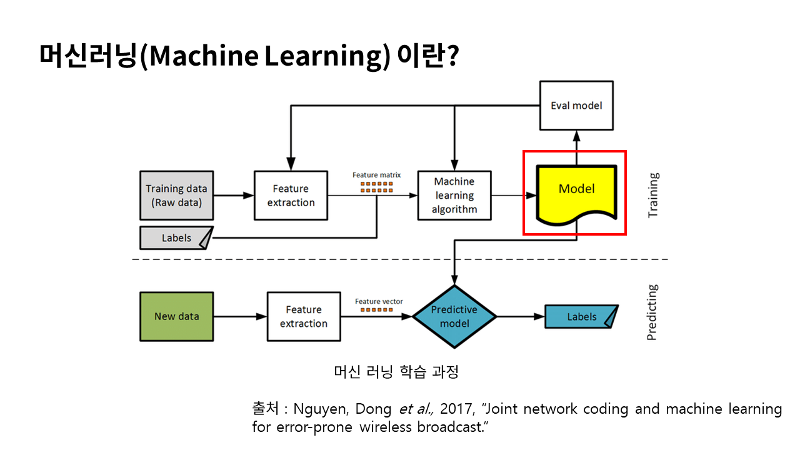
그림으로 보면 머신러닝은 크게 학습 단계와 예측 단계로 구분이 가능한데요. 훈련시킬 데이터를 머신 러닝 알고리즘에 적용해서 학습시키고, 이 학습 결과로 모델이 생성되요. 예측 단계에서는 학습 단계에서 생성된 모델을 새로운 데이터를 적용하면 결과를 예측하는 구조에요. Feature extraction이라는 것은 특성 추출이라고 하는데요. 참고로 모델이라는 것은 AI가 학습 단계에서 얻은 최종 결과물로 가설이라고도 이야기해요. 예를 들어 “입력 데이터의 패턴은 A와 같다.” 라는 가정을 AI에서는 모델이라고도 합니다. 모델의 학습은 첫번째로 모델이나 가설을 선택하구요. 두번째로 모델을 학습 및 평가합니다. 그리고 세번째로 평가를 바탕으로 모델을 업데이트 하는 과정을 거치게 됩니다. 우리는 앞으로 AI를 공부하면서 수많은 모델을 다루게 될텐데요. 이를 통해 최적의 모델을 찾아 일반화 하는것이 AI를 공부하는 이유가 될 수 있습니다.
|
|
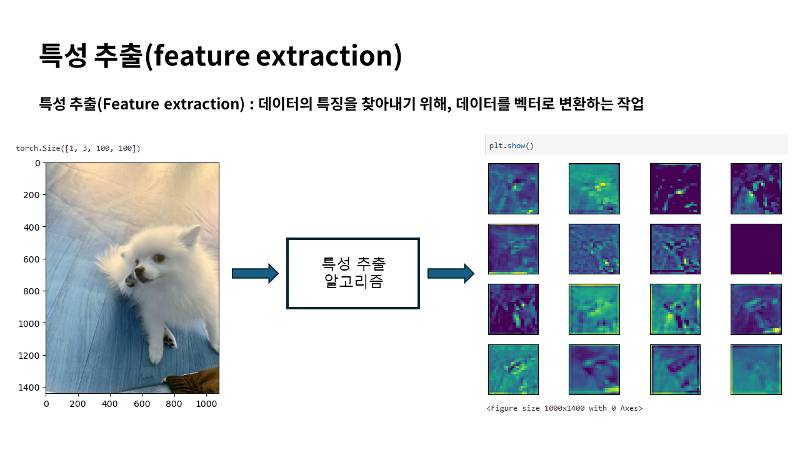
특성 추출은 머신러닝에서 컴퓨터가 스스로 학습하거나 컴퓨터가 입력받은 데이터를 분석하기 위해 사용되는데요. 사람이 인지하는 데이터를 컴퓨터가 인지할 수 있는 데이터로 변환해 주어야 해요. 이때 데이터별로 어떤 특징을 가지고 있는지 찾아내고, 그것을 토대로 데이터를 벡터로 변환하는 작업을 특성 추출(feature extraction)이라고 하게 됩니다. 예시로 제 친구가 키우는 강아지 사진을 컴퓨터가 어떻게 받아들이는지 특성추출 과정을 일부 시각화 시켜 보았는데요. 형태를 알아볼 수가 없죠. 이렇게 컴퓨터는 우리와 같은 결과를 보지 않는 것을 알수가 있네요. 하지만 이러한 과정을 우리가 직접 계산하지는 않을거에요. 딥러닝으로 넘어가면 이러한 과정도 컴퓨터가 처리를 하게 됩니다.
|
|
머신러닝은 그리고 목적에 따라 분류와 회귀로 나눌 수 있는데요. 표처럼 분류와 회귀를 정의하게 됩니다. 먼저 분류는 주어진 데이터를 정해진 범주에 따라 나누는 것을 분류라고 하는데요. 분류는 문제의 아웃풋이 이산화, discrete된 값을 갖습니다. classification의 목적은 주어진 인풋 변수가 어느 discrete category에 속하는지 찾아내는 것을 이야기해요. 예를 들면, 종양이 양성인지 음성인지 진단하는 문제는 분류문제 이겠죠? Regression, 회귀는 변수가 두 개 주어졌을 때 한 변수에서 다른 변수를 예측하거나 두 변수의 관계를 규명하기 위해 사용하는 방법인데요. 여기서 사용되는 변수는 독립 변수와 종속 변수로 나눌 수 있어요. 독립변수는 예측 변수라고도 하는데요. 영향을 미칠 것으로 예상되는 변수를 독립 변수라고 이야기해요. 종속 변수는 기준 변수라고도 하는데요. 영향을 받을 것으로 예상되는 변수를 이야기하게 되요. 이때 두 변수 간의 관계는 타당성이 있어야 하는데요. 예를 들어 몸무게와 키는 둘간의 관계를 규명하는 용도로 사용되죠. BMI지수를 이야기할 때요.
|

|
그림으로 보면 좀 더 이해가 쉬울거에요. 왼쪽 그림처럼 모양이 다른 두 도형 데이터들을 선형 방정식으로, 이산화 시키는 것을 분류라고 하고요. 오른쪽 그림 처럼 불규칙하게 찍혀있는 점들을 연속된 값을 갖도록 예측하는 것을 회귀라고 해요. 하지만 우리는 단순하게 AI를 사용하고 모델을 만들 때 “이건 분류고 이건 회귀야”라고 이야기 하진 않습니다.
|

|
예를 들어볼까요? 전에 제가 AI를 사용해서 스팸메일을 필터링 할 수 있다고 했는데요. 수백만개의 메일 데이터들을 우리가 학습시킨다고 가정해 보겠습니다. 이러한 스팸 메일 분류 모델을 만들기 위해선 다음과 같은 고려 사항이 있을거에요. 첫째, 메일에 복권, 무료 등과 같은 스팸 관련 용어가 포함되어 있는지 여부. 둘째, 유사한 메일이 사용자에 의해 스팸으로 분류되었는지 여부. 셋째, 얼마나 자주 오는지 여부일겁니다. 당연히 스팸이냐 아니냐로 분류를 위한 프로세스가 들어가야 하겠죠? 그리고 이러한 기존의 분류를 토대로 앞으로 올 메일에 대해서 예측할 수 있어야 해요. 이때 필요한 것이 회귀입니다. 회귀는 분류완 다르게 과거 데이터를 기반으로 값을 예측할 수 있는데요. 둘의 공통점이라곤 오로지 예측을 위한 프로세스라고 할 수 있을겁니다. 얼핏 보면 유사해 보이지만, 명확하게 구분해야 합니다.
|

|
마지막으로 AI를 공부하면서 많은 알고리즘과 용어를 접하게 될텐데요. 앞으로 우리에겐 어떻게 적용할까? 라는 고민을 많이 하게 될거에요. 또 AI라는 도구가 계속 필요한 순간이 오리라 생각하는데요. 예를 들면, 머신러닝과 딥러닝중에 어떤걸 선택하지? 라는 생각이 들 수도 있어요. 하지만 주어진 데이터를 활용해서 어떤 결과를 얻고 싶은지에 따라 다르다고 생각합니다. 머신러닝은 선형을 다루기 때문에 간단한 데이터를 선형으로 보고 싶다면 머신러닝을, 비선형 데이터를 다루려면 딥러닝을 다뤄야합니다. 어찌되었든 AI는 데이터를 분석하고 얻고 싶은 결과를 도출하기 위한 도구일 뿐이라고 생각하면 좋겠습니다. |

ANN, DNN, CNN, RNN 개념과 차이
